The Consensus Showdown — 4 BFT Protocols on AWS
/ 8 min read
Table of Contents
TL;DR
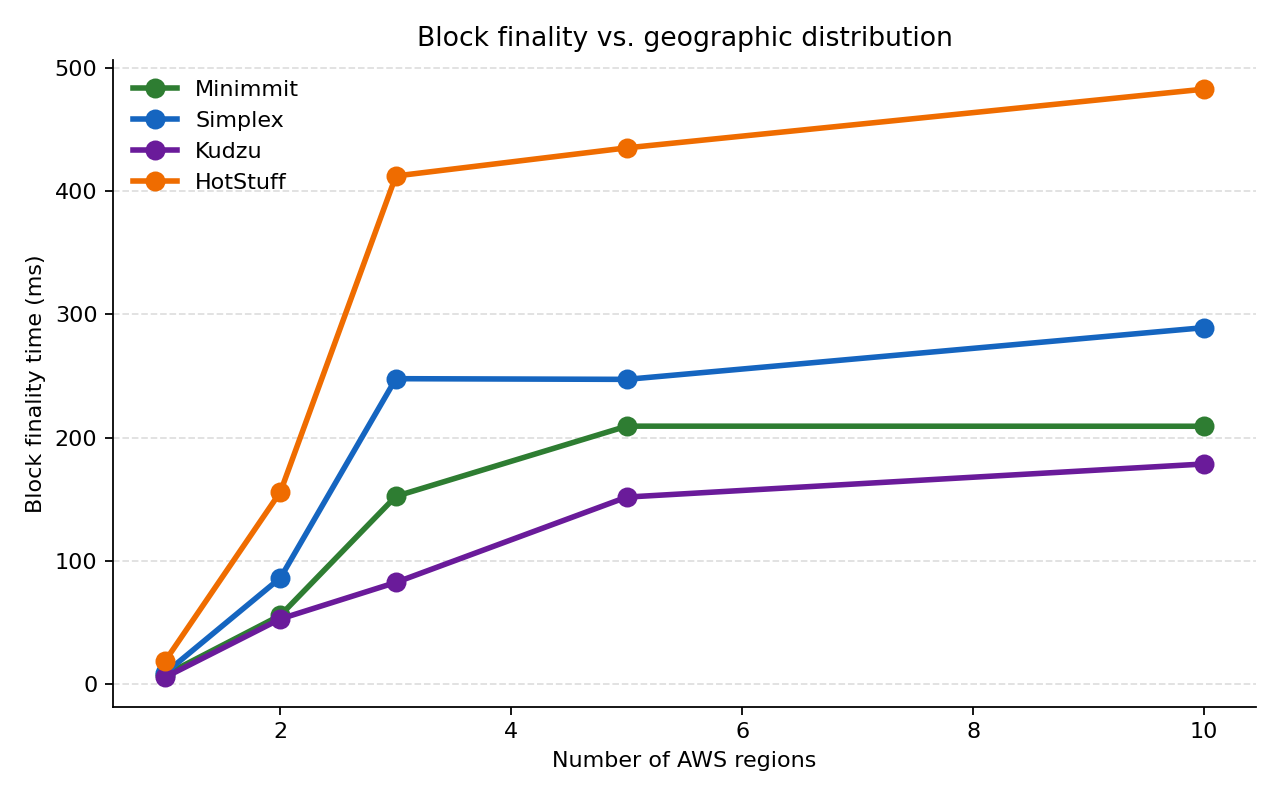
I ran HotStuff, Simplex, Minimmit, and Kudzu on the same realistic deployment topologies — from a single region up to a 10-region “alto-like” production spread — using the official commonware-estimator tool with embedded cloudping.co AWS latency data.
| Algorithm | 1 region | 2 region | 3 region | 5 region | 10 region (alto) | Rounds |
|---|---|---|---|---|---|---|
| Kudzu | 5 ms | 53 ms | 83 ms | 152 ms | 179 ms | 2 |
| Minimmit | 7 ms | 56 ms | 152 ms | 209 ms | 209 ms | 2 |
| Simplex | 9 ms | 86 ms | 248 ms | 247 ms | 289 ms | 3 |
| HotStuff | 19 ms | 156 ms | 412 ms | 435 ms | 483 ms | 5 |
- Phase count puts you in a tier. The two-round protocols (Kudzu, Minimmit) lead, Simplex (3) sits in the middle, HotStuff (5) trails — 2.7× behind Kudzu at production-like scale. With tiny messages this is mostly mechanical: fewer cross-WAN rounds, lower finality.
- The Kudzu/Minimmit gap here is not a real ranking. My setup measures block finality with default-size messages — finality between the two two-round protocols should be close, and Minimmit’s actual edge (shorter views → lower transaction latency) isn’t captured at all. See the Scope note above.
- 3 regions is where geography really hurts — finality jumps 2-3× compared to the 2-region baseline because the slowest validator-to-quorum edge now spans Pacific or Atlantic distances.
The full source — runner, parser, plots, and every raw output — is on GitHub: erenyegit/commonware-consensus-showdown.
Why this exists
The Commonware monorepo ships four production-ready BFT consensus implementations: HotStuff (the classical PBFT-descendant), Simplex (the team’s mainline design), Minimmit (a minimal-rounds successor), and Kudzu (the latest, optimized for two-round finality). Each has its own .lazy simulation file in examples/estimator/, so the question of which one is best, and when? is a single afternoon’s compute away.
I figured someone should answer it.
The setup
commonware-estimator is a deterministic event-simulator. You write the protocol as a tiny DSL (propose{...}, wait{...}, collect{...}), hand it an AWS region distribution, and it plays the protocol through real region-to-region latencies measured by cloudping.co. No live network, no flaky CI — every run is reproducible byte for byte.
I drove twenty (algorithm, topology) cells:
- 4 algorithms →
simplex.lazy,minimmit.lazy,hotstuff.lazy,kudzu_small_block.lazy(the only Kudzu file shipped without bandwidth limits). - 5 topologies →
1region_5peers:us-east-1:52region_5peers:us-east-1:3, eu-west-1:23region_6peers:us-east-1:2, eu-west-1:2, ap-northeast-1:25region_15peers: 3 peers each inus-east-1,eu-west-1,ap-northeast-1,sa-east-1,eu-central-110region_alto: the canonical 10-region distribution from the estimator README —us-west-1,us-east-1,eu-west-1,ap-northeast-1,eu-north-1,ap-south-1,sa-east-1,eu-central-1,ap-northeast-2,ap-southeast-2, three peers each (30 total).
For each cell I record the block finality time — the latency of the last wait/collect stage, averaged across every proposer rotation. That’s the end-to-end “I have a final block” wall-clock cost for the proposer.
Findings
1. Phase count sets the tier (but not the ranking)
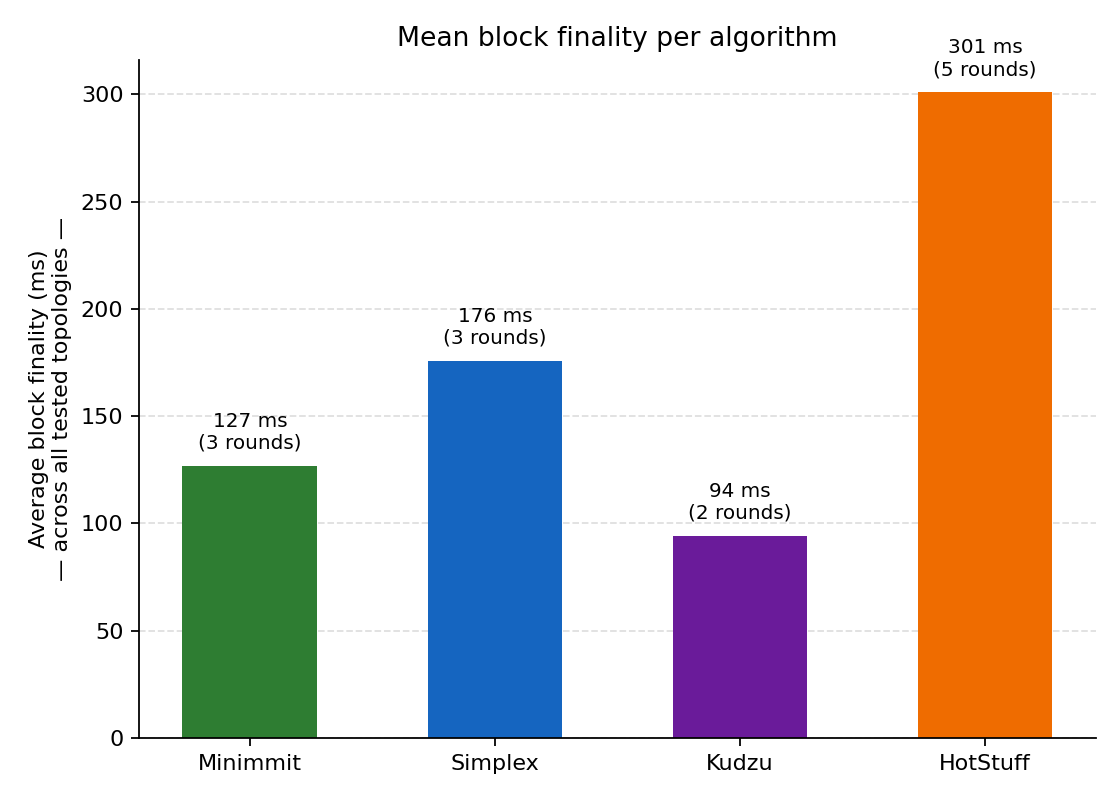
Averaged across all five topologies:
| Algorithm | Mean finality | Round count |
|---|---|---|
| Kudzu | 94 ms | 2 |
| Minimmit | 127 ms | 2 |
| Simplex | 176 ms | 3 |
| HotStuff | 301 ms | 5 |
Phase count is the dominant signal. As modeled in the shipped .lazy files, HotStuff runs the most wait/collect rounds, Simplex sits in the middle at three, and Minimmit and Kudzu finalize in two. Each extra cross-WAN round adds roughly one max-region-latency hop — so once you’re paying ~150 ms per round-trip through Tokyo and São Paulo, the round count acts as a fixed multiplier on the WAN budget. (The exact phase structure of each protocol is best read from the source; here I’m only counting the rounds the estimator actually plays out.)
It isn’t the whole story though: Kudzu and Minimmit are both two-phase but Kudzu still posts ~30 ms lower mean finality (and ~70 ms lower at the 3-region step). That gap lives inside the same phase budget, so it comes down to threshold rules and message structure — and, again, finality isn’t the axis Minimmit was tuned for. Round count puts you in a bucket; the design inside the bucket still matters.
2. Kudzu posts the lowest finality in every cell — but read the caveat
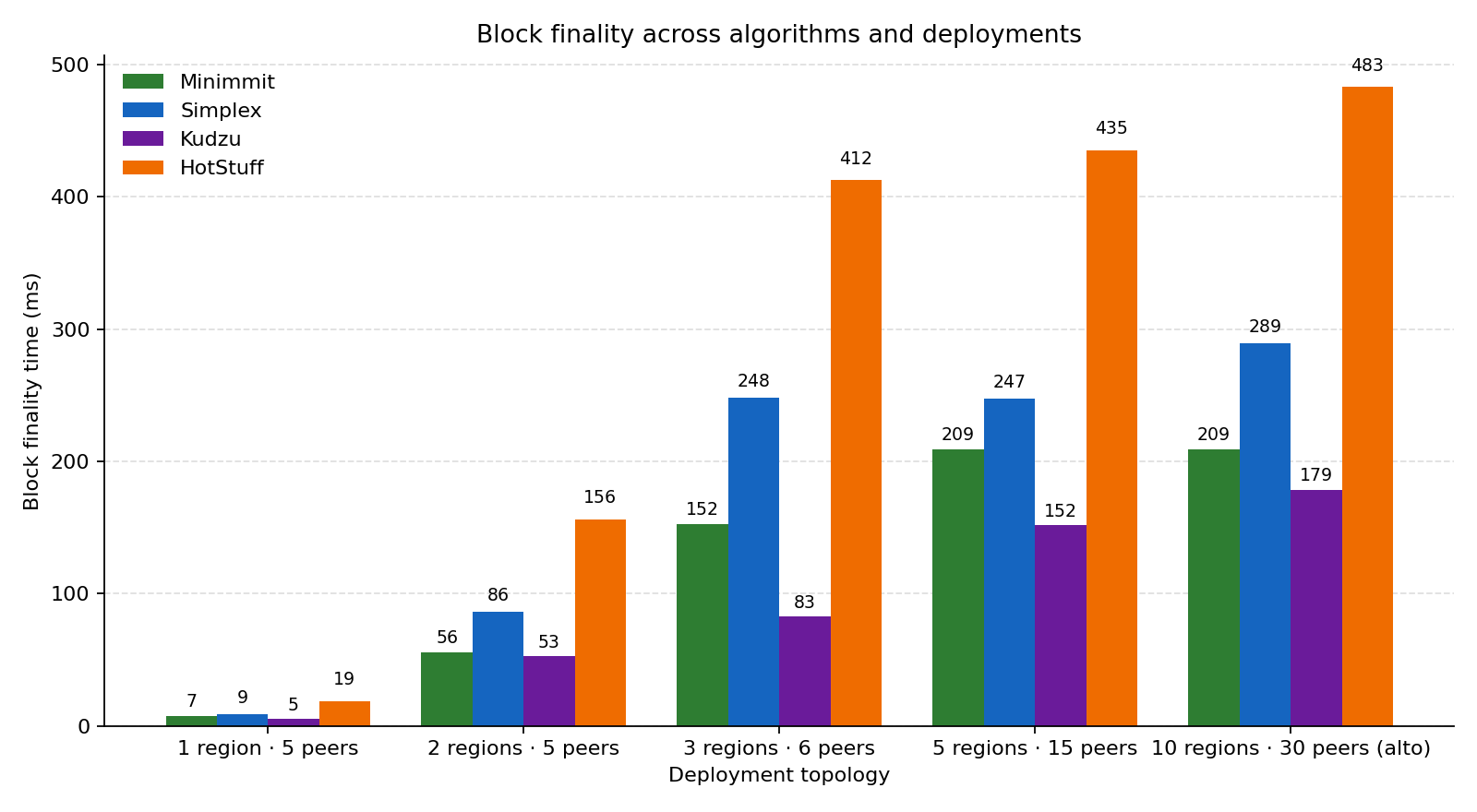
In raw block-finality terms, Kudzu comes out lowest in every individual cell of the matrix:
| Topology | Kudzu | Best non-Kudzu | Difference |
|---|---|---|---|
| 1 region | 5 ms | 7 ms (Minimmit) | 25% |
| 2 region | 53 ms | 56 ms (Minimmit) | 5% |
| 3 region | 83 ms | 152 ms (Minimmit) | 46% |
| 5 region | 152 ms | 209 ms (Minimmit) | 27% |
| 10 region | 179 ms | 209 ms (Minimmit) | 14% |
The caveat that matters: this isn’t an equal-footing comparison, and finality isn’t the metric Minimmit was built to win. I ran kudzu_small_block.lazy against the default minimmit.lazy — different message/coding assumptions baked in — and measured only block finality. As Patrick notes, the two should be very close on finality once you compare them fairly; Minimmit’s real advantage is shorter views and lower transaction latency, which my setup never touches. The 3-region “46%” is the kind of number that looks decisive but mostly reflects the specific .lazy configs I happened to pick. Treat this row as “Kudzu’s honest-path finality is competitive,” not “Kudzu beats Minimmit.”
3. Geographic distribution has a knee at 3 regions
Stepping from 1 region to 2 regions is ~10× across the board (you’ve just added a transatlantic hop). Stepping from 2 → 3 regions is another 1.5–2×, because the third region (ap-northeast-1 here) introduces the slowest edge in the topology — the Pacific crossing. After that, adding more regions has diminishing returns: the protocol is already bounded by the slowest pair, and adding eu-north-1 or sa-east-1 doesn’t move that bound much.
5 regions and 10 regions are barely distinguishable in three out of four algorithms. That means for these workloads, the cost of going global is paid in full at 3 regions — pick the right three and you’ve already captured most of the latency tax.
4. The 10-region “alto” deployment is surprisingly cheap
The estimator README ships an --distribution recipe that mirrors the deployment of Alto, Commonware’s reference blockchain. It’s ten regions and thirty peers, and you’d reasonably expect a finality cliff. In practice:
- Kudzu: 179 ms
- Minimmit: 209 ms
- Simplex: 289 ms
- HotStuff: 483 ms
Even HotStuff finalizes in under half a second on a truly global topology. The cost of Byzantine fault tolerance on the open internet, with 30 validators across every continent, is between 180 ms and 480 ms depending on which algorithm you pick. That’s an empirical lower bound to internalize before complaining that “BFT is slow.”
How to reproduce
# 1. Get the monorepo and this repo side-by-sidegit clone https://github.com/commonwarexyz/monorepo.git ~/Code/monorepogit clone https://github.com/erenyegit/commonware-consensus-showdown.gitcd commonware-consensus-showdown
# 2. Run the matrix (4 algorithms x 5 topologies = 20 simulations, ~20s total)python3 scripts/run_matrix.py
# 3. Flatten to CSV and re-plotpython3 scripts/to_csv.pypython3 scripts/plot.pyopen plots/ # macOS; use xdg-open on LinuxNotes & limitations
- Finality is not the same as transaction latency. This is the big one (h/t Patrick). I measured block finality — how long until a proposed block is final. Minimmit was optimized for shorter views, which lowers the time a transaction waits before it’s even proposed. Two protocols can have near-identical finality and very different transaction latency. My charts only show the first axis, so they undersell what Minimmit was actually designed to do. The simulations at the end of the Minimmit paper compare Kudzu and Minimmit on equal footing across all of these axes.
- Block size and erasure coding are out of scope here — and that’s a bigger deal than it sounds. I ran the default-payload variants, so the matrix mostly measures “fewer rounds win.” The interesting Kudzu vs. Minimmit comparison only shows up once bandwidth and coding are in play (the
*_large_block.lazyand*_large_block_coding_50.lazyfiles). That’s the follow-up. - The cells aren’t strictly equal-footing. Kudzu only ships a
kudzu_small_block.lazywithout bandwidth limits, so I compared it against the defaultminimmit.lazy. Different assumptions; don’t read the per-cell deltas as a clean ranking. - The estimator is event-driven, not a real network. It models region-to-region latency from cloudping.co and (optionally) bandwidth caps, but doesn’t simulate TCP slow-start, packet loss, OS scheduling jitter, or signature verification CPU cost. Treat these as a floor on finality time.
- Adversarial conditions are out of scope here. The matrix uses the honest-fast-path
.lazyfiles. The estimator shipsstall.lazyandsimplex_with_delay.lazyfor stress scenarios; those produce a different kind of plot (“how far can you push a quorum before liveness breaks”) and will get their own writeup.
Acknowledgements
All credit for the underlying mechanisms and the estimator tool itself goes to the Commonware team — in particular to their commonware-estimator DSL, which made this study a single afternoon of work rather than a multi-month engineering effort.
Reproducible run logs, per-stage breakdowns, and the full matrix runner live in the companion GitHub repo. PRs welcome if you spot a methodology bug.